Intro to Database Systems - Part 3 : The Relational Model
The entity-relationship model described in the previous lecture is a diagram. The main purpose is to clearly picture the constraints of the database to someone that is not necessarily coming from a computer science field.
The model that’s the most popular in Database Systems is the relational model: a representation of structuring data through relations between rows and columns. As seen in Lecture 1, relational database is composed by:
- schema : column headers ( same as attribute names)
- instances : the rows.
The schema for the database Students can be represented as Students(studID:string, name:string, login:string, faculty:string, gpa:real). It must contain:
- name of the relation
- set of attributes
- domain/type
The schema of the database is defined by the DDL : data definition language. It is used mainly to create and destroy databases and databases objects. The main operations are :
- CREATE: CREATE DATABASE employees; You can also create multiple tables within the same database: CREATE TABLE personal_info
- USE: specifies the database you wish to work with. If you are currently working in the sales database and wish to add something related to the employees db you’ll switch databases by issuing the USE employees command.
ALTER: allows you to make changes to the structure of a table without deleting or recreating yet. Say you want to modify a table in order to add something to it, the general procedure is :
ALTER TABLE table_name;
ADD column-name column-domain/type ;
As a practical example, we can have :
- ALTER TABLE supplier
- ADD supplier_name varchar2(50);
The last DDL that we’ll cover is the DROP operation: it removes the entire database objects from the Database System.

The Data Manipulation Language is used to manipulate data itself (vs Data Definition Language which is used to define data structures). It is incorporated most of the times in SQL databases. The main commands are :
- SELECT : used for retrieving rows from a table (most used command in SQL.
- UPDATE: modifies data of one or more records.
- INSERT : adds one or more records to a database table.
- DELETE: removes one or more records from a table depending on conditions passed as a parameter.
Accessibility in terms of querying time is one of the main advantages of using the relational model. The most common tool for it is SQL : Structured Query Language. It covers both defining relations (DDL) and writing/querying data (DML).
While defining data in the relational model, it is important to notice that every attribute must have a data type. SQL, as any programming language, provides various data types :
- CHAR(n): a char string of fixed length n
- VARCHAR(n): a string containing between 0 and n chars
- INT (also as INTEGER): type containing 4 bytes
- MEDIUMINT: 3 bytes
- SMALLINT: 2 bytes
- TINYINT: 1 byte
- BIGINT: 8 bytes
- FLOAT (also as REAL): has 23 bits of precision
- DOUBLE (also as DOUBLE PRECISION): has 52 bits of precision
- DECIMAL(n,d) : value of n digits with decimal point d positions from right.
- DATE: has format YYYY-MM-DD (can be compared or converted as string)
- time: has format 15:00:58 (can also be compared or converted as string)
- bit strings: sequence of bits, each having the value 0 or 1
- user defined domains: explicit conversions are required for those. A good way to remember this is the Mars Climate Orbiter, who crashed due to an error for mixing imperial and metric units without conversion.
This are 2 examples of using data types in SQL. Notice the fact that SQL is case sensitive, and also that we can attribute default values:
- CREATE TABLE Students (studID INT, name VARCHAR(20), login CHAR(10), major VARCHAR(20) DEFAULT ‘undefined’);
- CREATE TABLE Enrolled (studID INT, cid CHAR(8), grade CHAR(2))
To manipulate data, we can show 3 examples:
- INSERT INTO Students (sutdID, name, faculty) VALUES (53688, ‘Chang’, ‘Eng)
- DELETE FROM Students WHERE name = 'Chang’
- UPDATE Students SET faculty = ‘Science’ WHERE studID = 53688
- SELECT name, major FROM Students WHERE faculty = ‘Science’
We’ve already discussed constraints in the previous lecture. An integrity constraint ensures that changes made by authorized users do not result in a loss of data consistency. The designer specifies them when the DB is created and the DBMS checks if the condition is true when relations are modified. The domain definition is an example of integrity constraint.
- CREATE TABLE Students (studID INT NOT NULL, name VARCHAR(20), login CHAR(10), gpa REAL DEFAULT 0.0)
A general example of an integrity constraint is the key declaration: a set of attributes forming a candidate key for the entity set. In a database, we can have 3 types of keys:
- candidate key
- primary key
- foreign key
A candidate key is a set of columns allowing us to distinguish rows. It can uniquely identify a record without mentioning any other data. The attribute “First Name” won’t identify any record in a database of students. In this database, you can have Dan Crisan, but also Dan Smith. To make sure that you have the required row, the required student, you will also have to take a look at the “Last Name”. Hence, the combination “First name” + “Last name” is a candidate key.
In a banking database, the combination of the customer’s ID and a sequential number for each of his bank accounts is a valid candidate key. Also, the ISBN (product number) is a valid candidate key. The ISBN number is also an example of a primary key: a column or a combination of columns that uniquely identify a record. Only one Candidate Key can be a Primary Key.
Here are few similarities between candidate keys and primary keys:
- both can uniquely identify records in a database
- both has constraints UNIQUE and NOT NULL
- both can be single column or a combination of multiple columns
To differentiate a candidate key from a primary key, we can notice that:
- there can be multiple candidate keys in a db but only one primary key is permitted
- the following example : the ID and SSN number of an employee database are both candidate keys. The ID is the primary key because SSN is sensitive information and it’s less prone to be used. Also, the employee ID is a better measurement in querying for an employee. It has a closer relation to the database. (another example will be a student ID vs his email. Both are candidate keys, but the student ID has a closer relation to the student entity than the email)
In addition of candidate keys and primary key, databases also have foreign keys: they refer to a primary key in another table. It’s a key to define the relationships between tables. Say we have a StudentEvent table where the primary key is the EventID. The personInCharge is actually storing studentID… which is the foreign key to the Student table. It defines the relationship between Student table and StudentEvent table.
Another example is where in database Enrolled, studentID is a foreign key referring to database Students. This can illustrate the concept of referential integrity: when one table has a foreign key to another table, the concept of referential integrity states that you can’t add a record to the table that contains the foreign key unless there is a corresponding record in the linked table. In this example, we can not add a student to the database Enrolled if the database Students doesn’t contain this student. Referential integrity is achieved if we don’t have this inconsistency.
In a scenario where we have Managers and Employees as different tables, referential integrity maintains the following 3 rules:
- we can’t add a record to the Employees table unless the managedBy attribute points to a valid record in the Managers table.
- if the primary key in the Managers table changes, all affected records in the Employees table must be modified using a cascading update.
- if a record in the Managers table is deleted, all affected records in the Employees table must be deleted using a cascading delete.
This is an example of how we mention keys between the database Enrolled and the database Students in SQL:
- CREATE TABLE Enrolled (studID INT NOT NULL, classID CHAR(8) NOT NULL, grade CHAR(2), PRIMARY KEY (studID, classID) FOREIGN KEY (studID) REFERENCES Students)
Now what are the steps to go from an entity-relationship model to the relational model?
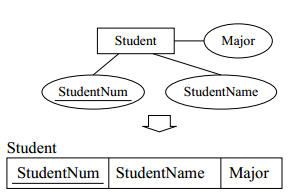
1) From entity sets to relations:
- Entity set E with attributes a1, …, an translates to table E with attributes a1, …, an.
- The primary key of the entity set is the primary key of a table.
- The entity set Student has attributes Major, StudentName and primary key StudID.
- CREATE TABLE Employees (empID CHAR(11) NOT NULL, name VARCHAR(20), salary REAL, PRIMARY KEY (empID))
- CREATE TABLE Departments (depID INTEGER NOT NULL, depName CHAR(20), budget REAL, PRIMARY KEY (depID))
- A graphical example is presented here :
2) From weak entities to relations
- Weak entity set E translates to table E
- Columns contain attributes of the weak entity set
- Columns contain attributes of the identifying relationship set (what links the weak entity to the dominating strong entity)
- Columns contain primary key attributes of the dominating entity set
- CREATE TABLE Dependants_Policy (polName CHAR(20) NOT NULL, dateofBirth DATE, cost REAL, empID CHAR(11) NOT NULL, PRIMARY KEY (polName, empID), FOREIGN KEY (empID) REFERENCES Employees)
- A graphical example is presented here :

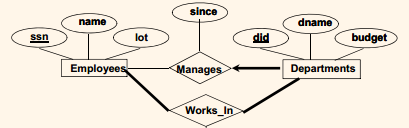
3) From relationship sets to relations (without constraints)
- Relationship set R translates to table R
- Columns contain attributes of the relationship set
- Columns contain primary key attributes of each component entity set
- CREATE TABLE Works_In (empID CHAR(11) NOT NULL, depID INTEGER NOT NULL, since DATE, PRIMARY KEY (emplID, depID), FOREIGN KEY (empID REFERENCES Employees, FOREIGN KEY (depID) REFERENCES Departments)
- A graphical example is presented here :

4) From ISA Hierarchies to relations
- If we declare A ISA B, every A entity is also considered to be a B entity. As a general approach, A has the attributes of B + its own attributes.
5) From aggregation to relations
*Remember that aggregation is a summary of our database: hence, we will have the primary key of each database and the descriptive attribute of the relationship between the relations (in this example : ssn, did, pid AND until).

6A) From relationship sets to relations (with key constraints - METHOD 1)
- Key constraint is just a fancy word of saying that we have Foreign keys, dependencies between tables.

- We just need to map the relationship to a table.
- The primary key of the dominating entity is the primary key of the table (example: departments have employees, hence the department id is the primary key of the table “Manages”)
- CREATE TABLE Manages( socialSecNum CHAR(11), depID INTEGER NOT NULL, since DATE, PRIMARY KEY (depID), FOREIGN KEY (socialSecNum) REFERENCES Employees, FOREIGN KEY (depID) REFERENCES Departments)

6B) From relationship sets to relations (with key constraints - METHOD 2)
- Another way of doing it is combining the dominating entity set with the relationship.
- What doesn’t change? We still keep the primary key of the dominating entity set.
- What does change? Since we combined the dominating entity set and the relationship, the new table now also contains the attributes of the dominating entity (Departments) AND just one foreign key: the one referencing the remaining entity set (in our case, Employees).
- CREATE TABLE Dept_Mgr( depID INTEGER NOT NULL, depName CHAR(20), budget REAL, socialSecNum CHAR(11), since DATE, PRIMARY KEY (depID), FOREIGN KEY (socialSecNum) REFERENCES Employees)
7) From relationship sets to relations (with key and participation constraints)
- If there is a participation constraint (every manager has a department), we highlight this in the table by adding a NOT NULL option to the parameter related to a mandatory participation.
- In our case, since department has a depID, every manager should be related to a department, hence his socialSecNum is mandatory associated to the depID.
- CREATE TABLE Dept_Mgr( depID INTEGER NOT NULL, depName CHAR(20), budget REAL, socialSecNum CHAR(11) NOT NULL, since DATE, PRIMARY KEY (depID), FOREIGN KEY(socialSecNum) REFERENCES Employees)
As a last word, referential integrity (consistency in data manipulation) is supported in SQL trough 4 options:
- ON DELETE NO ACTION (default)
- ON UPDATE NO ACTION (default)
- ON DELETE CASCADE
- ON UPDATE CASCADE
As an example, if we have 2 related databases Enrolled and Students, deleting the studID from one table will also delete the studID from the other table, if we mention ON DELETE CASCADE. This is done in order to preserve data consistency (referential integrity).
- CREATE TABLE Enrolled (studID INT NOT NULL, courseID CHAR(8) NOT NULL, grade CHAR(2), PRIMARY KEY (studID, courseID), FOREIGN KEY (studID) REFERENCES Students ON DELETE CASCADE ON UPDATE CASCADE)
Now that we are done with the rules to translate ER to relational model, here is a quick summary of the relation model:
- it is a tabular representation of data
- currently the most widely used
- the DBMS checks for violation of constraints : we have integrity constraints (primary and foreign keys) and domain constraints (can’t write an int where we expect a char)
- SQL implements the relational model, translated from the entity-relationship model.